Synthetic data is suddenly making very real ripples
Ready for the era of synthetic data? The implications for strategy and execution could be significant if marketers are willing to look long term.
 By Mark Ritson
By Mark Ritson

There is nothing like a decent perceptual map. Whether it’s derived from similarity scaling, vectors, multi-dimensional scaling (my favourite) or just a simple two-dimensional analysis – what you get is as close to a map of the market as you are ever likely to see.
They are a pain in the arse to build, of course. First you need the qualitative data to establish the attributes. Then you have to build a quant instrument to measure the brands against these attributes and across a representative sample of the market. Then comes the analysis. We provide a working template for multi-dimensional mapping on the Mini MBA in Marketing and it regularly boggles the minds of about 30 marketers. Like I said, a pain in the arse.
Perceptual map of automotive brands
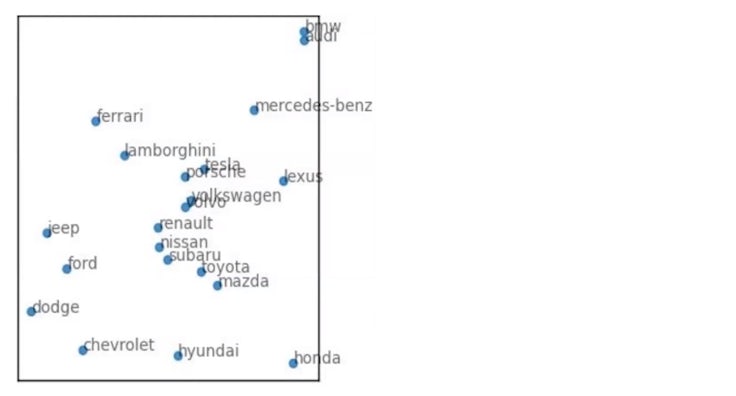
This is a very simple example of a perceptual map. It’s an analysis of how 21 automotive brands are perceived by American consumers. The chart above shows just the brands (and not the corresponding attributes). Each brand’s location relative to the rectangle is irrelevant. What you are looking for is the distance or proximity of brands from each other.
In this perceptual map, the data shows a familiar picture. BMW and Audi are seen as very similar. Jeep, Ford and Dodge also cluster in a similar perceptual space. As do Mazda, Toyota, Subaru and Nissan. Ferrari and Lamborghini race against each other in the centre.
Now look at distance. Honda is very different from Ferrari. BMW is not perceived as being similar to Hyundai. Honda occupies an oddly differentiated space, at least for US consumers. As does Lexus.
We would need to superimpose the attributes onto the map to delve further into the situation and diagnosis. Something most brand managers have done countless times before. There is nothing particularly surprising in any of this data. Or its analysis. But the data source is revolutionary. Because this perceptual map was built from a sample size of zero. In near real time. From synthetic data.
The era of synthetic data is clearly upon us.
Let me write that sentence again because it’s probably the first time you have ever read those words. But like the internet, omnichannel or Covid you will see this term so many more times in your career. New will soon become normalised. The perceptual map, above, was built from synthetic data.
GPT4 was used to collect the attributes and the brands by trawling the language of the internet. Brands and their associated attributes were then counted, ranked and compared across these attributes, and then the results displayed in multi-dimensional space for easy interpretation.
At this point you are probably asking a very good question: but is it correct? And of course, as a marketer, you are not asking about objective reality – about whether Jeep really is similar to Ford. There is no way to answer that question. What you are asking is whether the synthetic data comes close to actual perceptual data from organic human beings.
Is ChatGPT the next big threat to Google’s dominance in the AI market?
It’s a question that was anticipated by Professors Li, Castelo, Katona and Sarvary in their groundbreaking paper ‘Language Models for Automated Market Research: A New Way to Generate Perceptual Maps’. Don’t blame the professors for that clunky title by the way. Like much of the data contained within it was written by GPT.
In the paper the professors also collected quantitative similarity ratings from 530 participants and used that data to build the multi-dimensional perceptual map shown below – this time for real human data. And before you even bother to look, the answer to your question is ‘Fuck me’.
Perceptual map of automotive brands

The professors use a very complex ‘triplet method‘ to assess the congruence between synthetic and human data. They show that there is a 90% similarity between the two charts. But your eyes have already processed that similarity and your mind is now wandering across a lot of implications.
The era of synthetic data is clearly upon us. This study is one of more than half a dozen that have been completed recently by elite marketing professors at elite business schools, each with similar jaw-dropping results and knee-wobbling implications. Most of the AI-derived consumer data, when triangulated, is coming in around 90% similar to data generated from primary human sources.
Entering the synthetic era
This much progress in such a short space of time, with a modality like AI which is famed for its incremental learning ability, means that synthetic data is about to become a very real input into the world of marketing.
Again, if we take the sage perspective of Bill Gates, in the next year or two we will probably overstate that impact. But in the longer run the ability of AI to answer accurately for – and instead of – actual consumers has gigantic implications, many of which are still beyond us.
First, it turns the lead times required for data collection into a whisp of smoke. It cuts research costs to a tiny fixed cost fraction. And it enables an era where marketers don’t have to go to the market once with research. Just. Keep. Asking. Questions.
It also pretty much demolishes the distinction between qual and quant data given the language assessment tools AI is built upon appear equally adept at generating inductive data and then, in real time, measuring that data with nomological accuracy.
Second, AI could automate the process of analysis and decision making. Rather than discrete stages between data collection, analysis, strategy and execution, imagine the ability of AI to simply go to work and formulate the optimum targeting, positioning, objectives, media mix, pricing and so on, in real time.
The ability of AI to answer accurately for – and instead of – actual consumers has gigantic implications.
If synthetic data really is a tenable foundation then this second stage of AI implication, in which marketing strategy and execution is automatically and artificially built, is actually not that hard to envisage.
And that’s assuming the very high bar of AI replacing consumer perceptual data. There is a lower bar of more basic, but essential data that AI can also surely generate. Most marketers long for ESOV data for their brand but go without. Price elasticities are something that most marketers never get near. Most good brand managers know and love Romaniuk’s fame/uniqueness grid, but never get to build one for their own assets.
What if it could be done to the 90th percentile of accuracy (and beyond) with a keystroke? And what if the ESOV, pricing, targeting and DBA analysis models all start optimising across each other?
The implications for media planners, researchers, brand managers and marketing professors are super significant. I have spent my life railing against tactification and encouraging marketers to get back to the data and then to strategy before any tactical execution can be countenanced. Is my advice going to become superfluous by early 2030?
Levelling the research playing field
It’s easy for this column to now turn into future porn. I start frothing at the keyboard and end up passing out in a techno-orgasm of robot waiters and flying cars. It’s easy to lose the plot and a grip on reality. Certainly, the market research industry is already responding to the suggestion of synthetic data with all the grace and humility of their cigar chomping forebears from the 19th century American railroad industry.
Is the data reliable? What are the sources? Surely this is secondary data and therefore not reflective of current consumer tastes? These and many other points are being made and will be made to argue against synthetic data. Like the husband who discovers his wife’s (well worn) vibrator in the top drawer of her bedside table, there are lots of objections to be made. But most seem to confirm rather than contradict the potential impact of synthetic data in the long run.
But most of these challenges can be handled with simple triangulation. Provided one or two of the synthetic data points are replicated with primary human data most marketers will surely take speed, savings and sexy new tech over traditional approaches. History teaches us that this is the way of all marketing decision making. How else do we explain the triumph of that big black box of turds and spiders that is programmatic?
If you don’t invest 5% of your budget in research, you don’t know what you’re doing
And there is also the required observation that a lot of current, human derived market research and marketing planning is… well… pants. The wrong questions. The wrong analysis. The wrong sample.
We aren’t talking about AI replacing an ideal state here. If you ask most marketers whether they would trade their current research for instant synthetic data at a 90% level of confidence versus the human stuff, most would probably bite your hand off. And if I showed them a black AI box that would generate instantaneously a ‘perfect’ marketing plan – how many would back their manual, human approach against it?
And, lest we forget, there are huge swathes of the market that simply cannot access primary data. If I have heard one SME B2B marketer complain about being unable to build a funnel, I’ve heard it a hundred times. A lot of good marketers don’t even have a shitty empirical benchmark to beat with synthetic data, they have no benchmark at all. For that giant army of hard working, underserved marketers the advent of synthetic data is truly revolutionary.
It may take some time. Longer than most expect. But now that the toy stage of ChatGPT is coming to a close, the broader, deeper and longer running applications and implications of AI are coming into view.
Mark Ritson teaches – without the use of AI – on the Mini MBA programmes. You can check out the working paper described in the column (warning some of it is in Klingon) here






